Google Vertex AI SDK Vulnerability Exposes Cloud Environments to Remote Code Execution via Bucket Squatting


TL;DR
- Vertex AI SDK uses predictable naming, allowing attackers to perform bucket squatting.
- Attackers can intercept model uploads without needing prior cloud project credentials.
- The vulnerability uses malicious 'pickle' files to trigger remote code execution.
- Lack of ownership verification in the SDK staging process enables this exploit.
A nasty security flaw recently surfaced in the Google Cloud Vertex AI SDK for Python, leaving cloud environments wide open to remote code execution (RCE). The researchers who dug this up have dubbed it "Pickle in the Middle." It’s a classic case of convenience biting back: the SDK uses predictable, deterministic naming conventions for temporary staging buckets. This allows attackers to engage in "bucket squatting," effectively intercepting model uploads before they ever reach their intended home.
The vulnerability, discovered by the sharp minds at Unit 42 by Palo Alto Networks, zeroes in on the google-cloud-aiplatform SDK. Because the staging process lacks any real ownership verification, an attacker can simply guess the bucket name the SDK is about to use, create it first, and wait for the victim to dump their model data right into the attacker's lap. From there, injecting a malicious payload is trivial.
The "Pickle in the Middle" Mechanics
Why does this happen? It comes down to how the Vertex AI SDK handles staging when a developer doesn't bother defining a custom bucket. When you kick off a model upload, the SDK automatically generates a bucket name based on a predictable pattern—usually something like project-vertex-staging-region. Since that pattern is public knowledge, an attacker can anticipate the exact name of the bucket a project will try to use in a specific region.
If the attacker beats the victim to the punch and creates that bucket, the SDK just rolls with it. It doesn't stop to ask, "Wait, do I actually own this?" It just proceeds to upload the model data. The real nightmare starts with the SDK’s reliance on the Python pickle module. By swapping out the legitimate model file for a malicious one packed with a serialized payload, the attacker can trigger arbitrary code execution the moment that model is loaded or processed by the victim’s infrastructure.
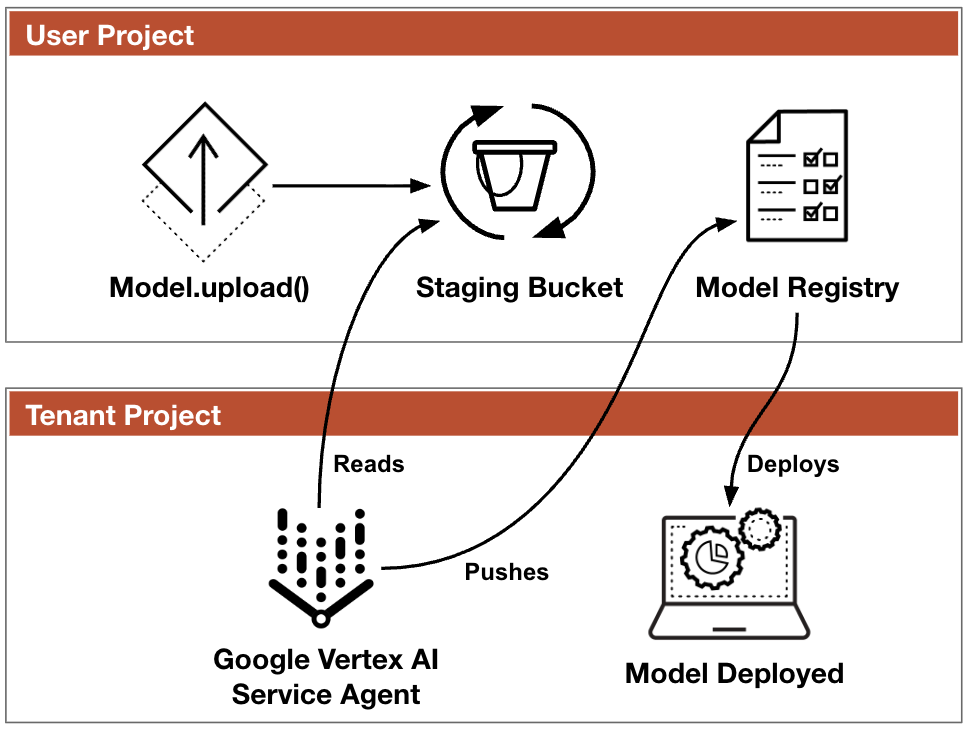
What makes this particularly dangerous is that the attacker doesn't need a single credential or any initial foothold in the victim’s Google Cloud project. It’s an external attack that weaponizes the SDK’s own automation. As highlighted by The Hacker News, this bypasses standard perimeter defenses by turning a "helpful" feature into a massive security hole.
Impact and Remediation
For any organization relying on Vertex AI to manage their machine learning pipelines, this is a serious wake-up call. Because the RCE happens within the serving infrastructure, the potential for lateral movement, data theft, or total system compromise is massive.
Google pushed out a fix in version 1.148.0 of the SDK on April 15, 2026. If you’re using this SDK, check your version immediately. If you’re behind, update. There is no middle ground here.
| Component | Status |
|---|---|
| Affected SDK | google-cloud-aiplatform |
| Vulnerable Versions | 1.139.0 and 1.140.0 |
| Remediation Version | 1.148.0 or later |
| Attack Vector | Bucket Squatting / Pickle Deserialization |
As CSO Online correctly pointed out, patching is the primary defense. Beyond that, stop letting the SDK guess your bucket names. Explicitly define your staging buckets. It’s a small extra step that saves you from a world of hurt.
Why the SDK Logic Failed
The Vertex AI Model Registry is designed to make moving artifacts from local machines to the cloud seamless. But "Pickle in the Middle" exposes the inherent danger of prioritizing "ease of use" over basic security validation.
When the SDK goes to stage a model, it checks if the bucket exists. If it doesn't, it creates it. If it does exist, it assumes it’s the right one. That’s the flaw. It never checks if the bucket actually belongs to the project performing the upload. This gap in the trust model is exactly what allows an attacker to sit in the middle of your workflow and hijack your data.
Securing Your AI Pipeline
The vulnerability is patched, but the lesson remains: your machine learning supply chain is only as strong as its weakest link. If you’re managing AI infrastructure, keep these principles in mind:
- Ditch the Defaults: Stop relying on automated naming conventions. Explicitly define your storage paths and lock down access to those buckets.
- Beware of Pickle: The
picklemodule is notoriously dangerous. If you’re handling data from anything other than a 100% trusted source, use a safer serialization format. Never trust serialized data from an external source. - Tighten IAM: Apply the principle of least privilege. Ensure your service accounts only have the permissions they absolutely need to do their jobs—nothing more.
- Watch the Perimeter: Keep an eye on your cloud storage activity. If you see unexpected buckets being created, especially in regions you frequently use for staging, investigate immediately.
Updating your dependencies is the bare minimum, but it isn't a complete security strategy. This incident serves as a stark reminder that even the most foundational tools in a cloud-native environment need to be treated with a healthy dose of suspicion, especially when they’re handling the heavy lifting of your data transfers. Don't let convenience override your security posture.